OCR/Data Extractor
TS-06-01
Automatically extract structured, actionable data from court forms, PDFs, contracts, and images to populate case management systems and support legal service workflows.
Task Description
Legal help providers routinely receive unstructured or semi-structured documents—such as court filings, notices, leases, scanned intake forms, handwritten notes, and correspondence—that contain critical information needed for case management, legal analysis, and follow-up services. Manually reviewing and extracting key data fields from these documents is time-consuming, error-prone, and difficult to scale.
This task involves developing or using AI-enabled tools to scan and parse these documents, extracting relevant data points such as case numbers, party names, filing dates, rent demands, deadlines, court hearing times, and other procedural facts. The system transforms this information into structured formats that can be automatically imported into a legal aid organization’s case management system (e.g., LegalServer, Salesforce, Pika, etc.), CRM, or other databases.
This process should work securely and reliably on a variety of formats:
- Scanned PDFs and images (via OCR)
- Fillable or non-fillable court forms
- Emails and attachments
- Typed or handwritten intake notes
Depending on the level of sophistication, the system may include human-in-the-loop review for quality assurance or continuous learning mechanisms. The long-term goal is to reduce administrative overhead, ensure timely data entry, and make legal service delivery faster and more accurate.
How to Measure Quality?
Our Stanford Legal Design Lab team is working with a cohort of subject matter experts to develop quality rubric to assess OCR/data extraction performance.
OCR/Data Extraction Rubric
Rating: 1 = Not OK 2 = OK with cleanup 3 = Good
HARD FAIL (if any are true → Not OK)
☐ The output is not usable text/data (garbled, missing most text, or wrong file processed)
☐ Key fields are consistently wrong or swapped (e.g., case number becomes hearing date)
☐ The system gives no way to spot uncertainty (no confidence flags / no review view)
☐ Processing creates a privacy/security problem (uploads stored unnecessarily, no access control, unclear handling)
INPUT COVERAGE (basic capability check)
Can it ingest common “flat” legal docs?
☐ Ingests .png / .jpg / .tif / .pdf (including scanned PDFs)
☐ Handles multi-page documents reliably
Score (1–3): _____
Notes:
ACCURACY OF EXTRACTION (core correctness)
Did it correctly read the text/numbers and extract the right values?
☐ Key fields are read correctly (case number, party names, dates, amounts, addresses)
☐ Values are assigned to the correct field/label (no “field swaps”)
☐ Errors are rare and minor (not frequent character-level mistakes that change meaning)
Score (1–3): _____
Notes (examples of wrong fields/values): __________________________________
COVERAGE ACROSS DOCUMENT TYPES (works on real-world variety)
Does it work on different legal document formats?
☐ Works on scanned forms, letters/notes, screenshots, and contracts
☐ Works on both clean prints and messy scans (skew, stamps, faint text)
☐ Captures most required fields across formats (not just one “happy path” form)
Score (1–3): _____
Notes (doc types where it fails): _________________________________________
STRUCTURE + LAYOUT (tables, forms, “what belongs together”)
Does it preserve layout and correctly pair labels with values?
☐ Form fields are paired correctly (label → value stays together)
☐ Tables are captured with correct rows/columns (numbers stay in the right cell)
☐ Multi-column pages are read in the right order (no scrambled paragraphs)
Score (1–3): _____
Notes (table/layout issues): ______________________________________________
HANDWRITING (if present)
Can it read handwriting when it appears?
☐ Handwritten names/notes/dates are captured accurately enough to be useful
☐ When unsure, it flags handwriting fields for human review (doesn’t guess confidently)
Score (1–3): _____
Notes (handwriting misses): ______________________________________________
DATA CLEANLINESS (ready for downstream use)
Is the extracted data clean and consistently formatted?
☐ Dates are normalized (e.g., MM/DD/YYYY) and not ambiguous
☐ Names/addresses/amounts are cleanly parsed (no random symbols/noise)
☐ Currency/amounts are consistent (e.g., $1,250.00 not “I,25O.OO”)
Score (1–3): _____
Notes (cleanup needed):
ERROR TRANSPARENCY + REVIEW (trust + fixability)
Can a human quickly verify and fix mistakes?
☐ Flags low-confidence fields (blurry, conflicting, partial)
☐ Provides an easy review UI (highlighted fields on the source page)
☐ Allows quick correction/export of revised structured data
Score (1–3): _____
Notes:
OUTPUT + INTEGRATION (usable structured data)
Is the output easy to import into a case management system (CMS) or database?
☐ Produces structured output (CSV/JSON) with stable field names
☐ Field mapping is clear and consistent across runs
☐ Minimal manual rework needed before import
Score (1–3): _____
Notes (mapping problems):
SPEED + RELIABILITY (workflow fit)
Is it fast and predictable in real legal workflows?
☐ Finishes quickly for most documents (target: ~1 minute or less for typical docs)
☐ Doesn’t crash/time out on common files
☐ Produces consistent results when rerun on the same document
Score (1–3): _____
Notes:
OVERALL RESULT
[ ] NOT OK (any Hard Fail OR 2+ items scored “1”)
[ ] OK WITH CLEANUP (no Hard Fail; mostly “2”)
[ ] GOOD (no Hard Fail; mostly “3”)
QUICK EXAMPLES OF “KEY FIELDS” TO TEST (pick 5–10 per doc type)
- Case number - Court name/location - Party names (plaintiff/defendant)
- Address / property address - Hearing date/time - Document date
- Rent amount / amount claimed - Deadlines (e.g., “within 5 days”)
- Checkboxes (selected/unselected) if forms - Table cells (fees/ledger rows) if tables are present
Related Projects

Benny the Benefits Navigator
An AI-enabled platform that streamlines Social Security Disability Insurance (SSDI) and Supplemental Security Income (SSI) applications, to reduce completion time and improve accuracy, completeness, and approval rates.
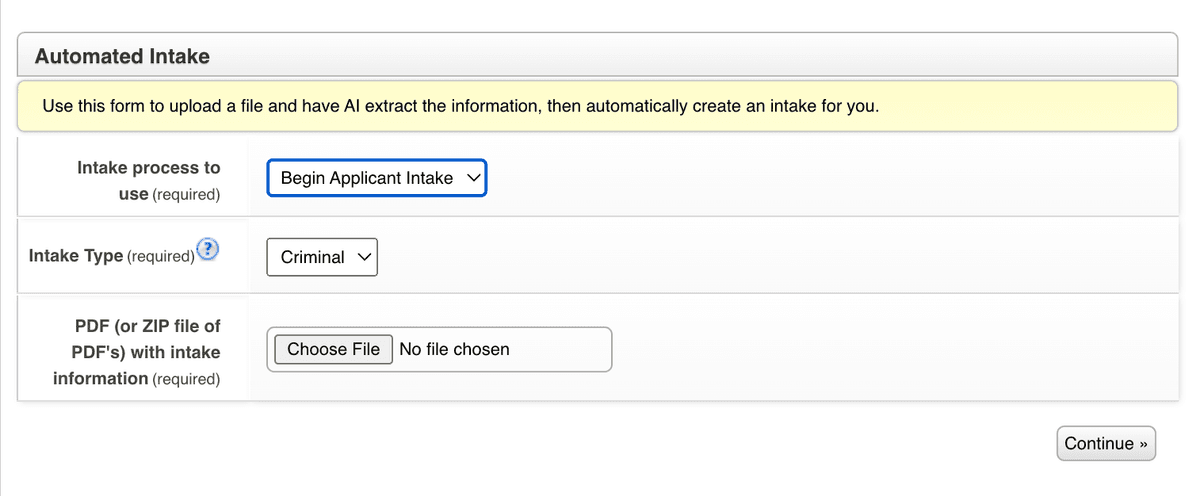
Automated Intake Data Extractor
LegalServer's Automated Intake Mode allows organizations to upload scanned or digital documents and automatically extract structured intake data into their case management system.

Lease Data Extractor with AI
A research prototype to extract structured data from images of Tenancy Agreements (typed, neat, and sloppy) using AI
Other Administration & Strategy Tasks
Explore related tasks in the same workflow category.