Legal Help Audience Categories
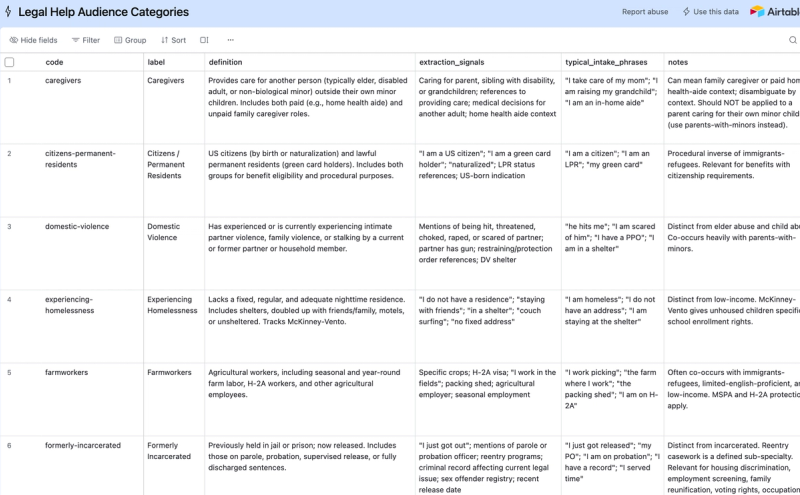
A controlled vocabulary for tagging the specific demographic groups/categories of pople that legal help organizations, services, and content are designed to serve.
Description
A canonical reference dataset for legal-help audience tagging. Used in two distinct ways: as the controlled vocabulary for the audience_served field across the Legal Help Data Standard's three core tables (Organizations, Services, and Content Index), and as the gold-label tagging vocabulary for legal AI evaluation datasets covering intake classification, content recommendation, and matching benchmarks.
The vocabulary covers four categories of audience tags in one flat namespace: demographic identity (seniors, veterans-military, lgbtq, native-american-tribal, parents-with-minors, people-with-disabilities, youth, farmworkers, immigrants-refugees, domestic-violence, caregivers); service-eligibility status (low-income, citizens-permanent-residents, receives-public-benefits, subsidized-housing); procedural and life-stage posture (self-represented, incarcerated, formerly-incarcerated, experiencing-homelessness, small-business); language access (limited-english-proficient); and a default catch-all (general-population).
Each term carries: a code in kebab-case for interoperability, a human-readable label, a plain-language definition, extraction signals a classifier can use to identify the tag from intake text, typical intake phrases that surface the tag, the term's source (LHC standard or v0.2 addition), prior names for migration from older vocabularies, and disambiguation notes covering common confusions with related terms.
Used by legal-aid organizations to describe their target populations on directory listings, by court self-help centers to scope service eligibility, by content publishers to tag who a guide or form is written for, and by AI-powered intake classifiers to extract structured audience tags from unstructured client intake (chat messages, hotline call transcripts, email inquiries, cross-agency referral notes).
Size: 22 terms total. Seventeen are part of the LHC Data Standard v0.1 release; five are v0.2 additions surfaced during AI-classifier evaluation work in 2025-2026.
Format: CSV, eight columns: code, label, definition, extraction_signals, typical_intake_phrases, source, prior_terms, notes.
Provenance: Maintained as the audience-served vocabulary of the Legal Help Data Standard at Stanford Legal Design Lab. The 17 core terms have been in operational use across statewide legal help directories and court self-help systems. The 5 v0.2 additions (limited-english-proficient, caregivers, formerly-incarcerated, receives-public-benefits, subsidized-housing) emerged from gaps identified during intake classification dataset construction and cross-agency referral note analysis.
Status: v0.2 (May 2026). Stable for production use. Versioning tracks the parent LHC Data Standard.
License: CC BY 4.0, matching the parent Legal Help Data Standard.
Citation: Stanford Legal Design Lab. Legal Help Audience Categories (v0.2). Legal Help Commons, May 2026.